[Avg. reading time: 15 minutes]
Storage Format
| Account number | Last name | First name | Purchase (in dollars) |
|---|---|---|---|
| 1001 | Green | Rachel | 20.12 |
| 1002 | Geller | Ross | 12.25 |
| 1003 | Bing | Chandler | 45.25 |
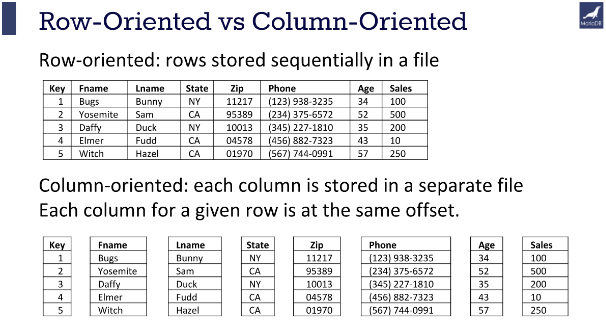
Row Oriented Storage
In a row-oriented DBMS, the data would be stored as
1001,Green,Rachel,20.12;
1002,Geller,Ross,12.25;
1003,Bing,Chandler,45.25
Best suited for OLTP - Transaction data.
Columnar Oriented Storage
1001,1002,1003; Green,Geller,Bing; Rachel,Ross,Chandler; 20.12,12.25,45.25
Best suited for OLAP - Analytical data.
Compression: Since the data in a column tends to be of the same type (e.g., all integers, all strings), and often similar values, it can be compressed much more effectively than row-based data.
Query Performance: Queries that only access a subset of columns can read just the data they need, reducing disk I/O and significantly speeding up query execution.
Analytic Processing: Columnar storage is well-suited for analytical queries and data warehousing, which often involve complex calculations over large amounts of data. Since these queries often only affect a subset of the columns in a table, columnar storage can lead to significant performance improvements.
CSV/TSV/Parquet
- Comma Separated Values
- Tab Separated Values
Pros
- Tabular Row storage.
- Human-readable is easy to edit manually.
- Simple schema.
- Easy to implement and parse the file(s).
Cons
- There is no standard way to present binary data.
- No complex data types.
- Large in size.
Parquet
Parquet is a columnar storage file format optimized for use with Apache Hadoop and related big data processing frameworks. Twitter and Cloudera developed it to provide a compact and efficient way of storing large, flat datasets.
Best for WORM (Write Once Read Many)
The key features of Parquet are:
Columnar Storage: Parquet is optimized for columnar storage, unlike row-based files like CSV or TSV. This allows it to compress and encode data efficiently, making it a good fit for storing data frames.
Schema Evolution: Parquet supports complex nested data structures, and the schema can be modified over time. This provides much flexibility when dealing with data that may evolve.
Compression and Encoding: Parquet allows for highly efficient compression and encoding schemes. This is because columnar storage makes better compression and encoding schemes possible, which can lead to significant storage savings.
Language Agnostic: Parquet is built from the ground up for use in many languages. Official libraries are available for reading and writing Parquet files in many languages, including Java, C++, Python, and more.
Integration: Parquet is designed to integrate well with various big data frameworks. It has deep support in Apache Hadoop, Apache Spark, and Apache Hive and works well with other data processing frameworks.
In short, Parquet is a powerful tool in the big data ecosystem due to its efficiency, flexibility, and compatibility with a wide range of tools and languages.
CSV vs Parquet
| Metric | CSV | Parquet |
|---|---|---|
| File Size | ~1 GB | 100-300 MB |
| Read Speed | Slower | Faster for columnar ops |
| Write Speed | Faster | Slower due to compression |
| Schema Support | None | Strong with metadata |
| Data Types | Basic | Wide range |
| Query Performance | Slower | Faster |
| Compatibility | Universal | Requires specific tools |
| Use Cases | Simple data exchange | Large-scale data processing |
These metrics highlight the advantages of using Parquet for efficiency and performance, especially in big data scenarios, while CSV remains useful for simplicity and compatibility.
Apache Arrow
Apache Arrow is an in-memory columnar data format designed for fast data exchange and analytics.
- Parquet is for disk
- Arrow is for memory
Arrow allows different systems to share data without copying or converting it.
Why Arrow Exists
Traditional formats focus on storage:
- CSV, JSON : human-readable, slow
- Parquet : compressed, efficient on disk
But once data is loaded into memory:
- Engines still spend time converting data
- Python, JVM, C++, R all use different memory layouts
Arrow solves this by providing a common in-memory columnar layout.
What Arrow Is Good At
- Fast in-memory analytics
- Zero-copy data sharing
- Cross-language interoperability
- Vectorized processing
Arrow is not a replacement for Parquet.
They work together.
| Feature | Apache Arrow | Apache Parquet |
|---|---|---|
| Purpose | In-memory analytics | On-disk storage |
| Location | RAM | Disk |
| Performance | Very fast, interactive | Optimized for scans |
| Compression | Minimal | Heavy compression |
| Use Case | Data exchange, compute | Data lakes, warehousing |
1: https://mariadb.com/resources/blog/why-is-columnstore-important/